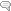When applications are moved to the Cloud (in this case to Azure), people get perception that their applications are highly available and up all the time. Usually, most of the Azure services has SLA of 99.95% which also leads to the high availability perception.
Let’s consider a business scenario. Assume, we have an online shopping application deployed on Azure as Platform as a Service. Application consists of below Azure services
- Azure Web App
- SQL Azure
- Blob storage
Conceptual architecture diagram of the application will look like this:

Assume application is deployed in the ‘North Central US’ Azure region.
What is wrong with this deployment? Everything should work fine and application should be available 99.95% of time. Here are few things to consider:
- 99.95% uptime is for individual service.
- This means if web app can be down for X number of hours and SQL database service can be down for Y number of hours. It’s NOT necessary both will down at the same time, they can be unavailable at different time
- So, even though each Azure service is within 99.95% SLA, your application might have more downtime!
- What if your web application has some edge case failures?
- For example, your application has memory leak issue and in some edge cases, it gets restarted and after restart it takes few minutes to start serving requests.
- Such scenarios might add up to application downtime
- Consider such issues happening in busy season, which may give bad experience to your application users and might leave bad impression about your application
- Application deployments
- Releasing new features or bug fixes to Production will make application unavailable for deployment duration
- Depending on how many times you do deployments, that time will add up to application downtime
- Un-expected Azure issues may end up in application downtime
Because of above reasons, Design for Failure is important!
Let’s work on designing our application (above sample scenario) for failure.
First step
Find out failure points. In the scenario, we have 4 failure points:
- Azure Web App
- SQL Azure
- Blob storage
- Application bugs
Second step
Find solutions for handling failures.
Azure Web App
Solution 1
You can have multiple instances of web app running in same region. This means running web app in scaled out mode. You can run Azure Web App on up to 10 instances within same region
- Issues with this approach
- If Azure region is having downtime then your application will face downtime
Solution 2
Deploy application in multiple region and manage traffic routing using Traffic Manager
- Deploy application in other region (sister region). In our scenario, deploy web application to South Central US region
- Use Traffic Manager to route users to appropriate instance of web application
- Now even if North Central US region is having issue, user requests will be served from South Central US region. I will explain how to configure Traffic Manager below.
SQL Azure
- Enable Geo Replication for SQL Azure database
- Database is now actively geo-replicated to secondary region. Geo-replicated database is read-only
- If primary region is having trouble, then make database from secondary region as primary (read/write) by stopping geo-replication. Connect application to database from secondary region.
Blob Storage
- Choose your blob storage mode as ‘Read-Access Geo Redundant’ so that your blob storage content are actively geo-replicated to secondary region
- In case of failure in primary region, you can connect applications to secondary region
After considering above solutions, newer application architecture will look like this:

Traffic Manager
Traffic Manager is used to manage routing of application users between multiple Azure regions. Traffic Manager can be configured in 3 different modes:
- Failover mode
- Performance mode
- Round robin mode
In our case we will use Failover mode

Traffic manager needs ping URL to detect application is available or not. One ping URL can be configured per region.

If Traffic Manager sees ping failures from Primary (for certain time ~120 seconds) region then it automatically diverts traffic to next secondary region. When it sees primary region is up then Traffic Manager will divert traffic back again to Primary region.
You can find more information about Traffic Manager here
Validation time
Let’s revisit some failure scenario:
- Azure Web App is facing issues
- Traffic Manager will redirect traffic to secondary region
- Once primary region is back then Traffic Manager will traffic back to primary region
- So, we are covered
- SQL Azure service is facing issues
- Stop the replication
- Change database connection string to point to database from secondary region
- So, we are covered
- Blob Storage is facing issues
- Change connection string to use blob from secondary region
- So, we are covered
- Application issues
- This is the same scenario as Azure Web App is facing issues (#1)
- Traffic manager will address this issue
- Application Deployments
- You can deploy applications to one region at a time and avoid application downtime during deployments too
After designing for failure, you may notice that application uptime is drastically increased! Now, applications are resilient to the Azure failures as well as application failures.
Moving applications to Azure –> Think about Designing for Failure!